GPT-5.5 完整評測:設計師視角的真實實測,三大場景拆給你看

2026年5月4日 下午 7:02
AI 設計

OpenAI 在 4/23 發了 GPT-5.5。我用了兩週,把它丟進設計師每天最吃時間的三件事——視覺探索、設計研究與書寫、自動化跑日常雜務——測下來,兩件事真的變快了,一件事被別人壓住。這篇拆給你看。
CHAPTER 01 / QUICK ANSWER
一句話結論:升級值得,但別被官方 benchmark 帶風向
GPT-5.5 是 OpenAI 自 GPT-4.5 以來第一個完全重訓的基礎模型,內部代號 Spud,2026/04/23 發布。OpenAI 自己拿出來秀的數字很漂亮——Terminal-Bench 2.0 拿下 82.7% 業界第一、SWE-bench Pro 58.6%、OSWorld-Verified 78.7%——但這些 benchmark 都是針對工程師工作流。設計師關心的是另一組問題:生圖品質有沒有變好?寫中文長文有沒有變人話?Agent 模式做我每天的雜事順不順?
我兩週的實測結論:生圖(Image 2 入口端)變快、Agent 變得能用、長文寫作仍然不行。如果你已經訂 ChatGPT Plus 以上,這個更新讓你的訂閱費更值;如果你還在猶豫要不要訂——還是 Claude Pro 優先。原因下面拆。
CHAPTER 02 / WHAT CHANGED
這代到底改了什麼
進設計師三大場景前,先把官方規格對齊。一般部落格寫得很滿但其實只有四件事真的有體感差別。
01
原生多模態
文字、圖像、聲音、影片都在同一架構處理。設計師最有感的點:丟一張參考圖進去,模型對視覺細節的理解明顯更精準。
02
Agent 升級
OSWorld-Verified 從上一代的 60% 級跳到 78.7%。模型自己會用工具、檢查結果、走完多步驟任務,不需要每一步都告訴它做什麼。
03
Token 變便宜
OpenAI 自己強調這代用「更少 token 達成同樣結果」。實際感覺是訂閱用戶撞 rate limit 的頻率明顯降低,重度使用者體感最強。
04
長上下文翻倍
MRCR v2(1M tokens 檢索)從 GPT-5.4 的 36.6% 直接翻倍到 74.0%。丟整本書、整份合約、整個專案資料夾進去,這代真的能讀懂。
▲ 注意第四點:長上下文這個進展影響最深,但設計師日常工作很少塞滿 1M token,所以體感最弱。後面講長文寫作那段會回頭吐槽這件事。
SPECS / 規格快照

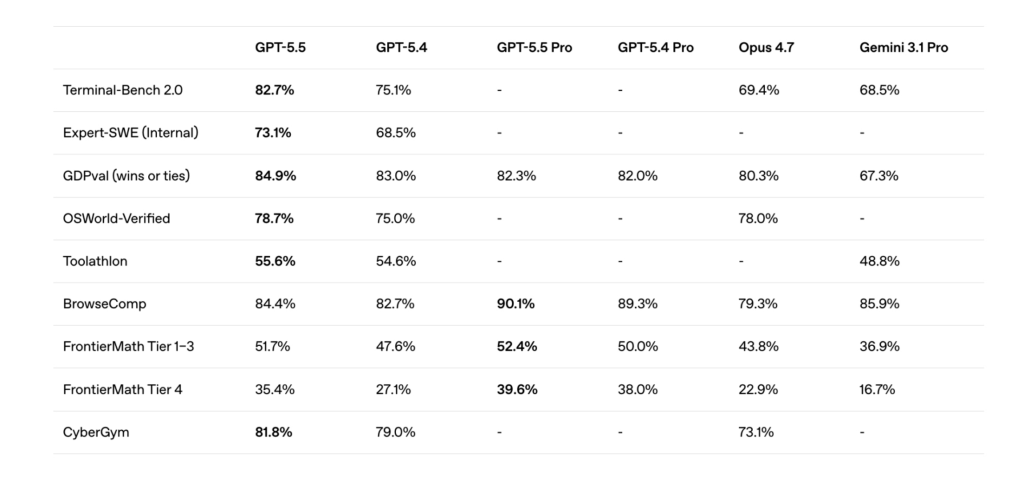
▲ OpenAI 官方公佈的 benchmark 對照。注意 GPT-5.5 在 Terminal-Bench、Expert-SWE、GDPval、OSWorld 都壓過 Opus 4.7,但 BrowseComp 一格 Opus 4.7 只有 79.3%、Gemini 3.1 Pro 拿 85.9%——這就是為什麼設計師不該只看單一 benchmark 做選擇。
CHAPTER 03 / SCENE 01|IMAGE 2
場景一|生圖:Image 2 沒變,但「進去 Image 2 之前」變快了
先講最容易誤會的:GPT-5.5 不是新的圖像生成模型。真正在生圖的是 Image 2——OpenAI 4/21 發的獨立圖像模型。GPT-5.5 在這個工作流的角色是「prompt 解析 + 結果評估」,是進入 Image 2 之前那層 reasoning 的引擎。
UPGRADE / 我的真實工作流時間
GPT-5.4 時代
我給一段中文 brief(「品牌提案 hero 圖,主題是高端護膚品牌,要金色金屬質感、暖夜配色、Editorial 雜誌感」)→ 模型常常理解錯方向,要回頭改 prompt 兩三次 → 第三次才生出方向對的圖。每張可用圖大約花 15 分鐘。
GPT-5.5 時代
同一段 brief 丟進去,模型直接抓到「金色金屬質感」跟「暖夜配色」的氣味,一次就生出方向對的圖,後面只剩細節調整。每張可用圖縮到 5–7 分鐘,大概省 60% 時間。
關鍵不是 Image 2 的 pixel 品質有多神,而是「GPT-5.5 看懂中文設計術語」這件事。「暖夜雜誌風」「卡片質感」「玻璃擬態」這類設計圈內行詞彙,上一代要解釋一輪它才聽懂,這代直接命中。對中文設計師來說,這是體感最大的進步。
不過要避免一個誤會
GPT-5.5 升級 ≠ Image 2 升級。Image 2 還是 4/21 那版,沒動。所以光看「圖出來的最終品質」,跟一個月前差不多。差別在於前置 prompt 解析的精準度——這是設計師體感最強、但 benchmark 完全不會測的事。
CHAPTER 04 / SCENE 02|LONG-FORM WRITING
場景二|長文寫作:抱歉還是不行
這段我必須誠實——GPT-5.5 寫中文長文還是不夠。OpenAI 釋出時強調「knowledge work 大幅進步」,這是真的,但「knowledge work」≠「中文長文」。這兩件事很容易混為一談。
01
短文寫作(500 字內):兩家平手
寫 IG 貼文、Threads 短篇、廣告 hook,GPT-5.5 跟 Claude Opus 4.7 差別不明顯。500 字以內的內容,AI 模型都已經到了商用門檻,差別只在風格偏好。
02
中等長文(1500–2500 字):Claude 開始拉開
寫設計提案說明、提案內文、品牌文案、服務說明,GPT-5.5 寫到 2000 字附近開始出現典型的「AI 翻譯腔」——句型重複、過度條列、用「不僅⋯⋯而且⋯⋯」這類教科書式連接詞。Claude 在這個區間還能保持節奏。
03
長文(3500 字以上):差距明顯
寫深度評測、長型案例分析、書評,GPT-5.5 結構穩但「嗓音」不穩——同一篇文章前段跟後段像兩個人寫的。Claude 寫 3500 字以上的中文長文還能維持嗓音一致,這是兩家最明顯的分水嶺。
這代差距不是品質高低,是嗓音一致性。Claude 的中文長文有結構感、有節奏,GPT-5.5 寫得正確但讀起來像翻譯。
關鍵猜測:GPT-5.5 的訓練資料中文比例可能較低,或者 RLHF 階段的中文評審員給的 reward signal 沒對齊「中文寫作的好品味」這件事。這是技術猜測,無法 100% 證明,但實測上兩家差距在這代沒縮小。
我的工作流分配:寫設計提案論述、做 case study 拆解、整理使用者研究筆記,這類需要嗓音穩定的長文還是用 Claude;用 GPT-5.5 寫 IG/Threads/廣告短文、客戶提案的條列說明沒問題。這代沒改變我的選邊邏輯。
CHAPTER 05 / SCENE 03|AGENT
場景三|Agent 自動化:這代真的能用了
這是 GPT-5.5 進步最大的場景。OSWorld-Verified 從上一代 60% 級跳到 78.7%,這個 benchmark 測的就是「模型自己操作真實電腦環境完成任務」。OpenAI 自己也最強調這塊。
01
研究爬查|大幅升級
Deep Research 這個功能本來就在,但搭 GPT-5.5 之後爬查邏輯明顯更聰明。我請它做「2026 年 Q2 設計師接案平台 ROI 比較」,上一代會給我 5 個老掉牙的平台,這代會主動把 Substack、Beehiiv 這類新型內容變現平台也納進來,我都沒提示。
02
表格/簡報生成|可以一次到位了
丟一段需求進去(「我要做使用者訪談分析,整理 12 位受訪者的逐字稿,找出共同 pain point + 提煉 3 個 design principle」),上一代給我的東西要改三輪才能用,這代第一次出來就 80% 對位。剩下的 20% 是個人偏好調整。
03
Codex 寫網頁|但我還是用 Claude
Codex(OpenAI 的 coding 介面)配 GPT-5.5 在 Terminal-Bench 2.0 拿 82.7% 業界第一,這是真的。但對設計師串 Figma plugin、寫 prototype 互動、做 design system 文件網站來說,Claude Code 的工作流更友善——直接 terminal、MCP 連 Figma 取 design token、改完直接寫回。Codex 介面偏軟體工程師。所以我寫程式還是用 Claude,這代沒翻盤。
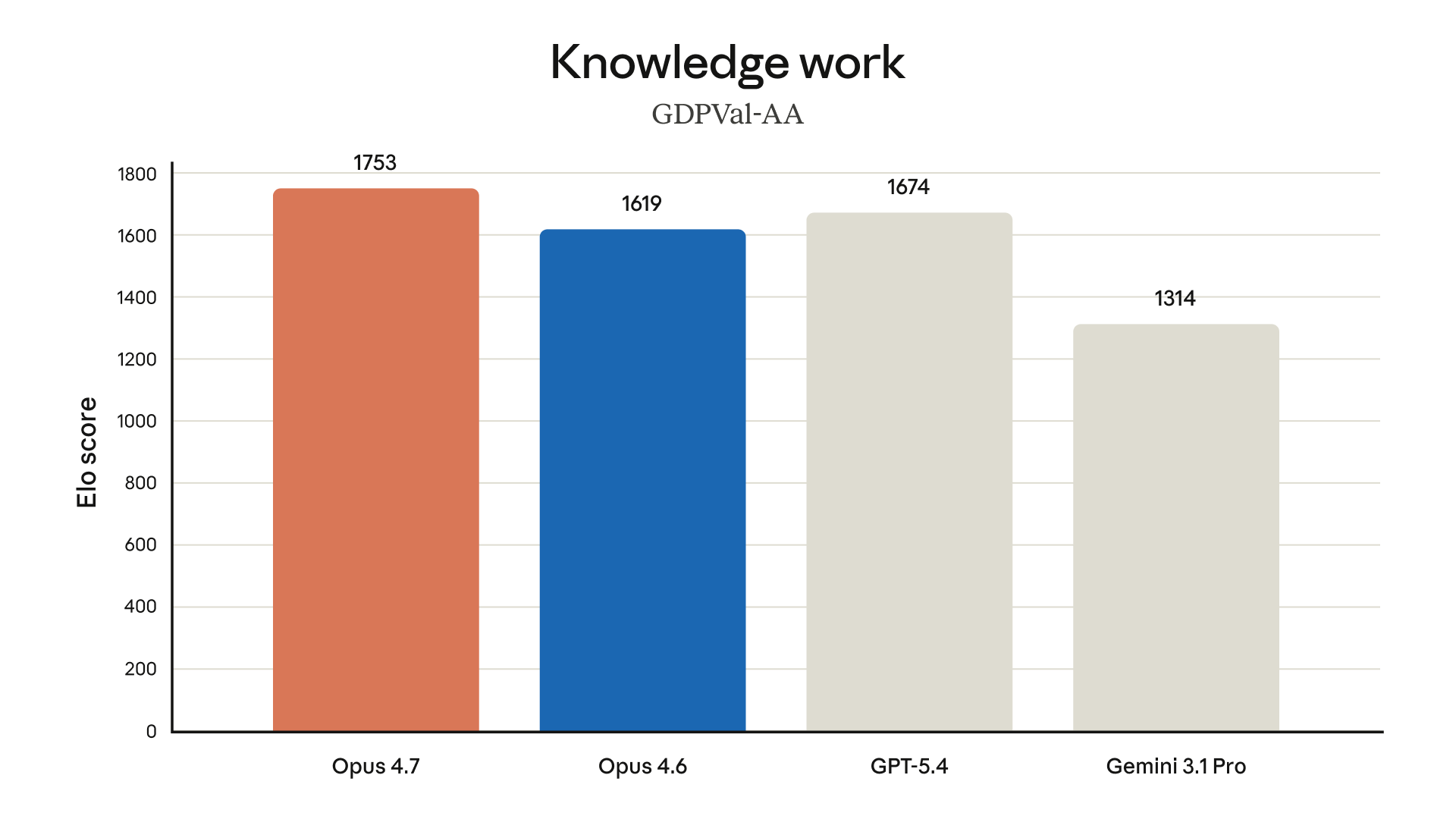
▲ Anthropic 在 4/16 發 Opus 4.7 時拿出來的 GDPVal-AA 知識工作測試。這份測試發布時 GPT-5.5 還沒上,所以對照組是 GPT-5.4。GPT-5.5 上線後雙方分數都會被重評。
CHAPTER 06 / SHOULD YOU UPGRADE
升級值不值:三類設計師三個答案
已訂 ChatGPT Plus / Pro
什麼都不用做,已自動升級
GPT-5.5 已經在 Plus、Pro、Business、Enterprise 自動 rollout。你開 ChatGPT 的模型選單就會看到。重點:去設定裡把 Auto routing 關掉、預設選 GPT-5.5,不然會被分流到舊模型。
還沒訂閱
Claude Pro 還是優先
這代 GPT-5.5 沒翻盤——對中文工作者來說,Claude 的長文寫作仍然不可取代。如果預算只有 $20,Claude Pro 拿到的價值大於 ChatGPT Plus。如果預算 $40,兩家各買一份是最佳組合(這在我上一篇對決文已經拆過)。
已訂 ChatGPT Plus 想升級到 Pro $200
看你的工作量
GPT-5.5 Pro 是 $200 訂閱才能用的版本,啟用「parallel test time compute」做更深度的推理。一般設計師日常用不到。我自己訂 Pro 是因為視覺探索撞牆時要拉很多參考、跑競品 UI 拆解跟使用者研究分析吃推理,Plus 額度撐不住,你要評估自己是不是也撞到這個門檻。
CHAPTER 07 / FAQ
最常被問的六個問題
Q1. GPT-5.5 是不是又一次「擠牙膏」更新?
不是。Agent 場景的 OSWorld-Verified 從 60% 級跳到 78.7%,是真的明顯升級。但對中文長文寫作這塊沒進步——所以對不同類型的設計師體感差很大。
Q2. GPT-5.5 跟 GPT-5.5 Pro 差在哪?
Pro 用「parallel test time compute」做更深度的推理,適合長型分析、複雜論文寫作、研究級爬查。日常工作用 GPT-5.5(標準版)就夠。Pro 只有 ChatGPT Pro / Business / Enterprise 訂閱才能用。
Q3. 免費用戶用得到 GPT-5.5 嗎?
用不到。免費用戶停在 GPT-5.3,且美國地區還會看到廣告。要 GPT-5.5 至少要 Plus $20。
Q4. GPT-5.5 跟 Claude Opus 4.7 哪個好?
錯誤的問題。應該問:什麼任務用哪個。生圖 / Agent / 研究爬查 → GPT-5.5 強。中文長文 / 寫程式 / 桌面自動化 → Claude 強。我上一篇〈ChatGPT vs Claude 設計師工作流大對決〉拆得更細。
Q5. API 要用 GPT-5.5 嗎?
看用量。GPT-5.5 的 API 定價 $5 input / $30 output,比 GPT-5.4 貴一倍,但用更少 token 完成同任務、retry 次數也少,實際結算下來不一定比較貴。Agent 場景跑大量 tool call 時,5.5 的 token 效率優勢很明顯。
Q6. GPT-5.5 知識截止日是什麼時候?
2025 年 12 月。問 2026 年的事它都靠 web_search 拉現場資料。設計師如果常問最新工具、最新趨勢,記得開啟搜尋功能。
SUMMARY / 重點整理
你只需要記住這五件事
→ 生圖場景變快
不是 Image 2 升級,是 GPT-5.5 看懂中文設計術語的能力升級,前置 prompt 解析省時間。
→ 中文長文沒進步
3500 字以上嗓音不一致的老問題沒解決。Claude 仍然是中文寫作首選。
→ Agent 真的能用
OSWorld-Verified 78.7% 是這代最關鍵的進步。Deep Research、表格生成、簡報雛形都比上一代少改一輪。
→ 已訂用戶價值更高
同樣 $20 月費,這代讓你的訂閱更值。但還沒訂的人不用因為這次升級就跳上船——Claude Pro 仍然優先。
→ 工具會輪流坐莊
這代 GPT 在 Agent 拉開、長文輸給 Claude、生程式碼平手。半年後可能整盤翻過來。重點是看清楚每個工具當下擅長什麼。
RESOURCES / 延伸資源
— OpenAI GPT-5.5 官方介紹:openai.com/index/introducing-gpt-5-5
— GPT-5.5 System Card:deploymentsafety.openai.com/gpt-5-5
— ChatGPT 訂閱方案:chatgpt.com/pricing
— 系列前一篇 ChatGPT vs Claude 對決文:rar.design/posts/chatgpt-vs-claude-designer-workflow
EDITOR'S PICK


AI 覺醒設計應用攻略
這是〈ChatGPT × 設計師完全攻略〉系列的第一篇——免費讀。後續九篇進去訂閱會員看:圖像生成完全指南、Veo 3 與 Seedance 多模型影片實戰、Custom GPT 設計顧問建立、Canvas 提案神器、Operator 自動化、UX 研究流程、文案產出 SOP、GPT Store 必裝清單。每篇都附我自己的 Prompt 模板與真實案例截圖。月繳 $399、年繳折合 $299/月。
GPT-5.5 不是革命。是把對的事做得更快。