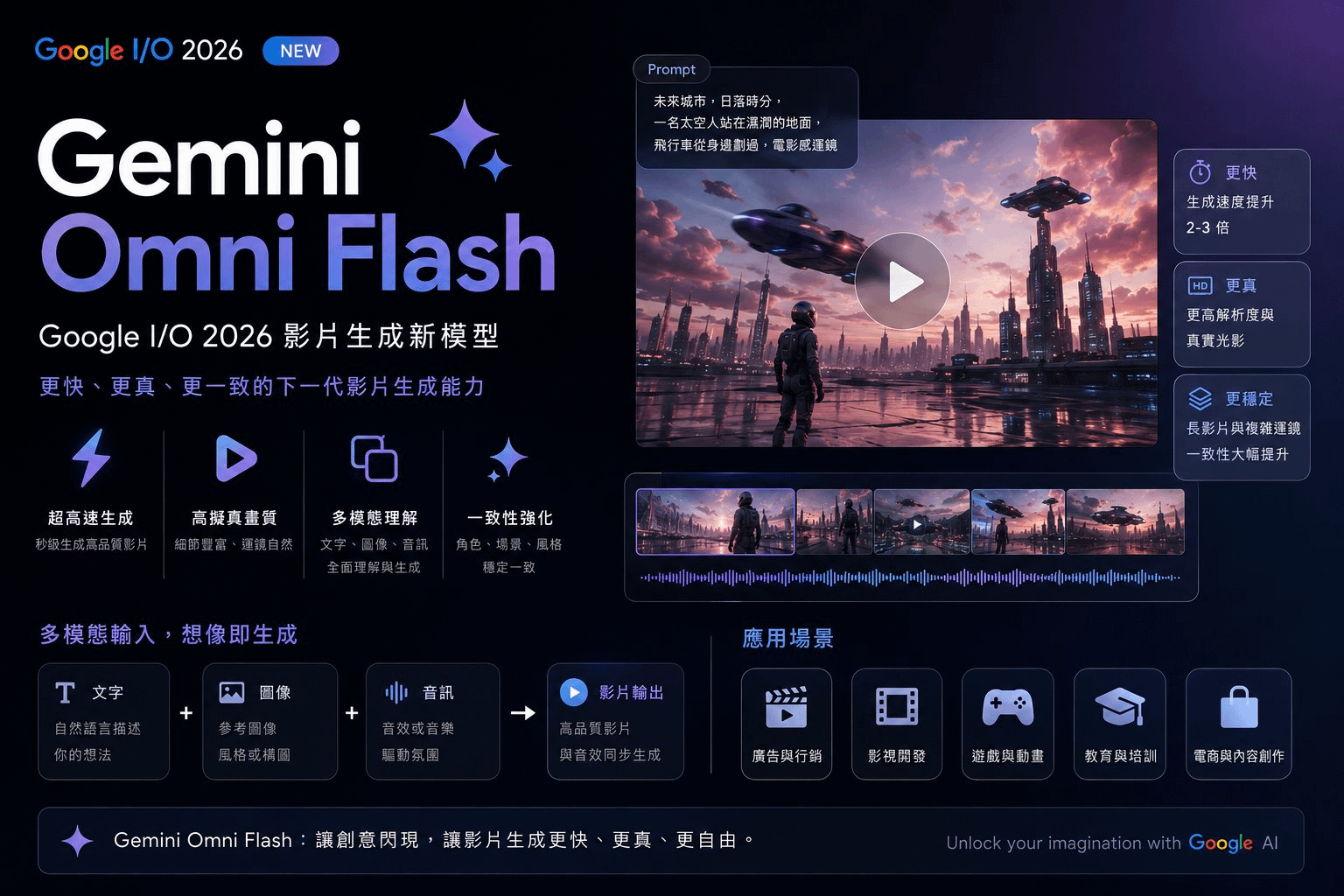
Gemini Omni Flash 是什麼?Google I/O 2026 影片生成新模型完整解析

2026年5月20日 上午 9:28
AI 設計AI TOOLS · GOOGLE I/O 2026

QUICK ANSWER
Gemini Omni Flash 是 Google 在 2026 年 5 月 19 日 I/O 發表的新一代多模態影片模型,核心能力是「用對話改影片」。給它一段你拍的素材,告訴它「把鏡子變成液態漣漪」,它能在保留原本角色、場景、物理連續性的前提下改寫,而且多輪指令會疊加記憶。今天起 Google AI Plus、Pro、Ultra 訂戶可在 Gemini app 與 Google Flow 使用,YouTube Shorts 與 YouTube Create App 免費開放,API 預計幾週後推出。單片上限 10 秒。
CHAPTER 01 · WHAT IS IT
Omni 是 Nano Banana 的下一步
昨晚的 Google I/O,真正該被設計師寫進筆記的不是 Gemini 3.5 Flash,也不是 Spark agent,是夾在中間的這顆模型——Gemini Omni Flash。它是 Google 一個叫 Omni 的全新模型家族的第一個成員,DeepMind CTO Koray Kavukcuoglu 親自寫文宣布。
官方那段敘事很值得拆開看。去年的 Nano Banana 把 Gemini 的智慧推進到圖片生成與編輯,讓人能修老照片、把草稿變設計稿。今年 Google 把同樣的邏輯往前一格,推到影片——但不是 Veo 的那種「文字生影片」,而是「任何輸入生影片,而且能用對話一直改」。
你可以丟一張圖、一段音樂、一支現成影片、一句指令,任意混合餵進去,它會推理出一個一致的輸出。然後你接著說「把場景換成下雨」「鏡頭拉到肩膀後方」「燈光跟著音樂節拍亮起來」,它記得前一步,在不破壞角色與場景連續性的前提下繼續改。
THREE PILLARS · OMNI'S CORE
01
對話編輯
多輪指令疊加,角色、物理、場景狀態跨輪保留
02
世界知識基礎
繼承 Gemini 對重力、流體、文化脈絡的理解
03
任意輸入混合
圖、文、影、音同時餵入,輸出一個連貫的影片
CHAPTER 02 · WHY IT MATTERS
從「生成一支」變成「改一支」
過去兩年的 AI 影片戰場大致長這樣:你打一段 prompt,模型吐一支影片,不滿意就改 prompt 再生一支。Sora、Veo、Runway、Pika、Kling、Seedance 全在這個範式裡比誰生得快、生得像、生得長。
Omni 把戰場挪到隔壁——video-to-video editing,而且是有狀態的多輪對話。這件事的差別比表面上大。當你能跟模型說「保留剛剛那個角色,只把背景換掉」「保留動作,把光換成夕陽」,你就不再是在「碰運氣抽卡」,而是在「跟模型協作雕刻一個畫面」。對設計師、影像工作者、廣告人來說,這是兩種完全不同的工作節奏。


— KORAY KAVUKCUOGLU, CTO GOOGLE DEEPMIND
"Every instruction builds on the last. Your characters stay consistent, the physics hold up and the scene remembers what came before."
這段話的關鍵字是 remember。當 AI 影片模型開始記得上一輪在做什麼,它就從「素材生成器」升級成「協作者」。Photoshop 的 history panel 之所以重要,不是因為它讓你 undo,而是因為它讓你「在一個延續的脈絡裡疊代」。Omni 把這個邏輯搬到了影片生成上。
CHAPTER 03 · HOW IT WORKS
三個核心能力,各自解一個痛點
一、對話式編輯:讓多輪修改變成創作流程
Omni 對話編輯的示範裡有一個讓人印象深刻的例子:小提琴家拉琴的場景,先換到沙漠環境、再讓小提琴消失、再把鏡頭切到肩膀後方。三輪指令疊下來,小提琴家本人、姿勢、運弓動作完全沒變,只有環境跟視角在動。
這在過去等於要重新 inpaint、重新 keyframe、重新對動作。現在只剩說話。


二、世界知識:讓物理跟邏輯不再出戲
Omni 不只看畫面像不像,它繼承了 Gemini 對物理(重力、動能、流體動力學)、歷史、科學、文化脈絡的理解。Google 給的示範:一顆彈珠在 chain reaction 軌道上連續滾動,鏡頭一鏡到底。這種多體碰撞、重力連鎖、無剪輯的場景,過去是 AI 影片最容易翻車的地方。


另一個示範更貼近設計師會用的場景:claymation 風格的蛋白質摺疊科普解說。短 prompt 進去,出來的是一段視覺解說型短片。這已經不是「生成漂亮畫面」,是「把概念翻譯成視覺敘事」。
三、任意輸入混合:把素材、節奏、風格全打進同一個 prompt
Omni 可以同時吃圖、文、影、音(語音目前先開放,其他音訊類型陸續上)。官方有個示範把這件事用到極致:一張參考圖、一段參考影片、一首參考音樂,prompt 寫「以 image_0 為基底、像 video_0 那樣 light up、跟 audio_0 的節拍同步」,出來是一支 sci-fi 風的角色行走 cycle,踩在節拍上。
這套輸入語法的意思是:你不用再把「風格」「動作」「節奏」三件事分開做。把該有的引用都丟進去,Omni 自己接。


▲ Google DeepMind 官方介紹影片。Source: Google for Developers
CHAPTER 04 · GETTING STARTED
在哪用、多少錢、什麼上限
Google 這次的上架節奏蠻乾脆。今天起 Omni Flash 全球同步開放,鋪在四個地方:Gemini app、Google Flow(Google 的 AI 創作工具)、YouTube Shorts、YouTube Create App。前兩個要 Google AI 訂閱(Plus、Pro 或 Ultra 任一個都行),後兩個免費。開發者 API 預告「幾週內」推出。
10s
PER CLIP
$0
YOUTUBE SHORTS
3
PAID TIERS
10 秒這個上限有意思。Google DeepMind 產品總監 Nicole Brichtova 跟 TechCrunch 講得很白:這不是模型能力的天花板,是一個「先讓更多人用得起」的部署決定。短期內大部分人也還不想做超過 10 秒的影片,所以先把算力撥給更廣的接觸面。更長的版本之後會推,Pro 版也在路上。
另外一個小設定:Omni 提供「Avatar」功能,可以建立你自己的數位分身,用你的臉跟聲音生影片。要拿獎、要登月、要拍 vlog,都可以。
CHAPTER 05 · IN PRACTICE
設計師可以怎麼把它接進工作流
10 秒、可對話改寫、支援風格參考——這個工具型態天生適合三件事。
✦情境化的產品展示。你有一張產品圖,想生一段 10 秒、有節奏、有環境氛圍的展示影片。過去要去找 motion designer,現在自己丟圖+音樂+一句場景描述,先生第一稿,再用對話微調光、角度、場景。
✦概念視覺化。提案要解釋一個抽象機制(演算法、工作流、產品邏輯),過去畫 storyboard 加旁白,現在直接 prompt「claymation 風格的 X 解說」,出一段視覺解說。
✦影片素材改寫。你拍了一段不錯但場景不對的素材,可以保留主角跟動作、只換背景或光線氛圍,當作社群短片或廣告素材的修改版。這在過去要靠 rotoscoping 跟 compositing,現在是一輪對話。
我個人會把它擺在 Seedance 2.0 旁邊用——Seedance 強在「從零生」的視覺密度,Omni 強在「拿著現成素材繼續改」。兩個工具的甜蜜點不一樣,但要做 YouTube Shorts、IG Reels、廣告 demo 時,你會發現有 Omni 在身邊蠻舒服的,特別是免費版直接內建在 YouTube Shorts 裡這件事,對短影片創作者根本是降維。
CHAPTER 06 · LIMITS
三個現階段的天花板
Google 自己也沒藏。第一,10 秒的單片長度——前面講過,部署決定不是模型上限。第二,音訊與語音的編輯先沒開放。你能做「avatar 用自己聲音講話」,但不能拿一段現成影片改裡面的對白。Google 說這塊要「負責任地」想清楚再上,理由心知肚明:選舉、惡作劇、深偽,風險太大。
第三,所有 Omni 生成的影片都帶 SynthID 的隱形浮水印,可以透過 Gemini app、Chrome 裡的 Gemini、Google Search 去驗證。Google 在 I/O 上講 SynthID 已經標記了超過 1000 億筆內容。這是 Google 對「內容來源辨識」的押注,長期看也是 Omni 能繼續開放更多能力的前提。
CHAPTER 07 · COMPARED TO
跟 Veo、Seedance、Higgsfield 怎麼分
Veo 3 / 3.1 還會繼續活著,但定位變得清楚:Veo 走「文字、影像生影片」的高品質純生成路線,Omni 走「任意輸入+對話改寫」的編輯導向路線。同一個 Gemini 體系下兩條線並進。
外部競爭那塊,ByteDance 的 Seedance 2.0 在公開 benchmark 的視覺品質一直在領跑,Kling 3.0 在中文市場壓著打。獨立測試者的初步反應是:Omni Flash 的「生成本身」未必贏這兩個,但「對話編輯」這條軸幾乎沒有對手。
Google 真正的籌碼從來不是「我的模型最強」,是 distribution。Omni 一發表就鑲進 Search、Gemini app、Flow、YouTube 四條軌道,你不需要去裝什麼新工具、申請什麼 waitlist。打開手機裡的 Gemini 或是 YouTube Shorts,它就在那。其他人要拚通路,Google 拚的是它已經有的通路。
CHAPTER 08 · TAKEAWAYS
為什麼這次該認真打開來玩
我看 Omni 的角度跟看 Nano Banana 那時很像。當時很多人覺得 AI 圖片編輯已經被 Photoshop+Firefly 滿足了,Nano Banana 沒什麼新意,可是它把「圖層概念換成對話」這件事真的做順了之後,設計師的修圖節奏整個被改寫。Omni 在影片這層做了同樣的事。
10 秒、無音訊編輯、API 還沒到,這些限制都會在接下來幾個月被一一打開。真正該被記住的是這條方向線:AI 影片從「抽卡」進入「協作」。下一個會被影響的工作,是 motion designer 跟 social media editor 的日常 70%。
如果你今天還沒摸過 Omni,有 Google AI Plus 訂閱的話就打開 Gemini app 試試;沒有訂閱的話,YouTube Shorts 的 Remix 入口這週開,完全免費。先用一個你拍過的素材丟進去,跟它對話三輪——你會直接體會到「對話編輯」這四個字的份量。
延伸閱讀:想看 I/O 2026 整場的全貌、Gemini 3.5 Flash 怎麼定位、Spark agent 在做什麼,可以去看 Google I/O 2026 完整回顧。
RELATED · I/O 2026 系列
HUB · 完整回顧
Google I/O 2026 重點整理:Gemini Omni、3.5 Flash、Universal Cart 一次看懂 →
這篇是 I/O 2026 第一天 keynote 的全景概覽——Gemini Omni、3.5 Flash、Universal Cart、Android XR 一次看完,搭配其他 4 篇深度拆解一起讀,就能拼出整場發表的全貌。


FAQ
常見問題
Q:Gemini Omni Flash 跟 Veo 3.1 是同一個東西嗎?
A:不是。Veo 3.1 還在,定位是純文字、圖片生影片的高品質生成路線。Omni 是全新的家族,主打多輸入、對話編輯。兩條線目前並存。
Q:Omni Flash 免費嗎?
A:看入口。YouTube Shorts 跟 YouTube Create App 完全免費。Gemini app 跟 Google Flow 要 Google AI Plus、Pro 或 Ultra 任一訂閱。台灣可以直接訂閱。
Q:單支影片最長多久?
A:目前上限 10 秒。Google 官方說這是部署決定,不是模型限制,之後會放寬。Omni Pro 也在路上,但沒有時間表。
Q:可以拿來改別人拍的影片嗎?
A:技術上可以,版權上你自己負責。另外 Omni 現階段不開放編輯音訊跟語音內容,主要是避免被拿去做深偽影片,「avatar 用自己聲音講話」是例外。
Q:有 API 嗎?
A:還沒。Google 預告「幾週內」會給開發者跟企業客戶。先觀望就好,正式釋出再做整合決定。
Q:Omni 生的影片可以商用嗎?
A:要看你的訂閱方案條款,Plus、Pro、Ultra 各有不同的商用條款,建議發案前到 one.google.com 看清楚當前版本的 Terms。所有生成影片都會有 SynthID 隱形浮水印,這件事是必然的,改不掉。