Claude Opus 4.8 是什麼?跑分、誠實升級與設計師的實際用法

2026年5月29日 下午 1:41
AI 設計AI TOOLS · 2026


QUICK ANSWER
Claude Opus 4.8 是 Anthropic 在 2026 年 5 月 28 日推出的旗艦模型升級,價格跟 Opus 4.7 一樣。跑分全面小幅提升,但這次真正的重點是「誠實」——它更會主動標記自己不確定的地方、少亂下結論,官方說它讓自己寫的程式碼帶 bug 卻不吭聲的機率,比上一代低了大約四倍。對把 AI 當生產工具的設計師來說,這比多兩個百分點的跑分有感得多。
CONTENTS
今天半個 AI 圈又洗了一輪版面。Anthropic 丟出 Claude Opus 4.8,距離上一代 Opus 4.7 只隔了四十一天——這在他們的節奏裡算是用衝刺的速度在出牌。同一天他們還宣布完成 650 億美元的 H 輪募資,估值衝到 9650 億美元,正式越過 OpenAI。模型跟錢一起發,氣勢做得很足。
但我看完發表第一個念頭是:跑分這次沒什麼好吹的。多數項目相對 4.7 只動了一兩個百分點,電腦操作那一項甚至只進步 0.6%。如果你只看那張表,會覺得這是一次「擠牙膏」更新。
真正值得寫一篇的,是 Anthropic 這次把賣點壓在一個你想不到的字上——誠實。一個更會說「這裡我不太確定」的模型。聽起來不像功能,但對任何把 AI 接進真實工作流、要靠它的產出交差的人來說,這可能是這半年最有感的一次升級。這篇我會拆三件事:跑分到底怎麼讀、誠實升級為什麼對設計師重要、還有那個藏在模型選單旁邊、多數人會用錯的新開關。

CHAPTER 01 · WHAT IS IT
這次更新到底是什麼
一句話:Opus 4.8 是 Opus 4.7 的小步快跑版,同價格、跑分小升、可靠度明顯變好,外加三個新東西上桌。如果你還在用 4.7 的工作流,幾乎可以無痛換過去。
先用一張圖把它的定位講清楚:


價格維持原樣是這次的隱形重點。一般用量還是每百萬輸入 token 5 美元、輸出 25 美元;快速模式的速度拉到 2.5 倍,而且比之前便宜了三倍。能力往上、成本沒往上,這在現在這個各家模型輪流漲價的時間點,本身就是一種競爭動作。
跟模型一起上線的還有三樣:
一是 claude.ai 跟 Cowork 多了「努力程度」開關,讓你決定 Claude 花多少力氣回答(後面會細講,它比看起來重要)。二是 Claude Code 的 dynamic workflows,能規劃任務、同時跑上百個子代理、驗證後再回報,目前研究預覽、限 Enterprise/Team/Max。三是 Messages API 可在任務中途更新指令、不打斷快取,給用 API 串自動化流程的人用。
至於規格面,這四個重點記著就好:


CHAPTER 02 · THE NUMBERS
跑分怎麼讀,還有那一格輸掉的數字
官方拿 Opus 4.8 跟自家 4.7、GPT-5.5、Gemini 3.1 Pro 排在一起比。先看圖,再聽我說哪幾格值得停下來。
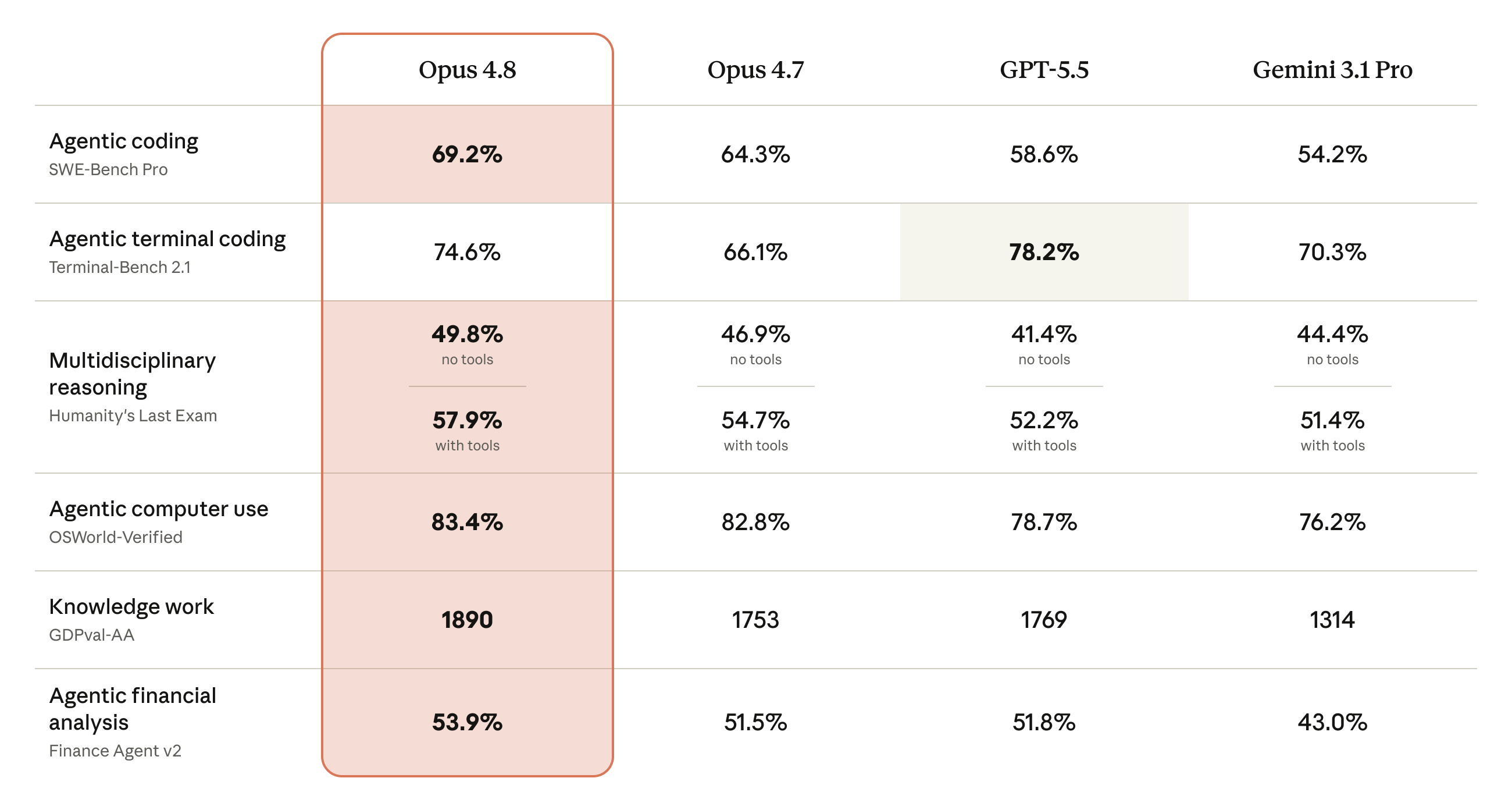
該贏的有贏。寫程式的 SWE-Bench Pro 從 4.7 的 64.3% 拉到 69.2%,把 GPT-5.5 的 58.6% 跟 Gemini 的 54.2% 拉開一個身位。知識工作那項 GDPval-AA 拿到 1890 分,對手分別是 1769 跟 1314,差距更明顯。財務分析也小升。
但我要你看的是第二列:終端機程式(Terminal-Bench 2.1)。GPT-5.5 拿 78.2%,直接壓過 Opus 4.8 的 74.6%,而且這格還被特別標粗。Anthropic 在自己的發表圖裡,留了一格輸給對手,沒有修掉。
更狠的是底下那行小字。footnote 裡他們補了一句:如果 GPT-5.5 改用對方自家的 Codex CLI 環境跑,分數是 83.4%——也就是說,他們不只承認輸,還主動把自己輸得更難看的版本寫出來。
這個動作先記著。它不只是跑分上的小瑕疵,它其實就是這次發表真正想講的那件事的活廣告。下一章會把這條線收起來。
CHAPTER 03 · THE REAL UPGRADE
真正的升級:它開始承認「我不確定」
AI 模型有一個老毛病:它常常太有自信。明明證據很薄,還是會拍胸脯說「搞定了」。你用它寫程式、寫文案、做分析,最累的不是它做不出來,是它做錯了還一臉篤定,逼你自己回頭抓蟲。


Opus 4.8 這次主打的,就是治這個毛病。官方說它更會主動標記不確定的地方、少做沒根據的宣稱。而且給了一個具體數字:它讓自己寫的程式碼帶著瑕疵卻不吭聲的機率,比上一代低了大約四倍。早期測試的金融分析師回饋也是同一件事——它會主動指出輸入和輸出裡的問題,而這些問題以前都得使用者自己抓。
Anthropic 還跑了一份對齊評估。結論是 Opus 4.8 在「欺騙」「配合濫用」這類失準行為上的比例,比 4.7 明顯降低,幾乎追平他們目前最對齊的 Mythos Preview。下面這張官方圖看得最清楚——長條越矮越好。
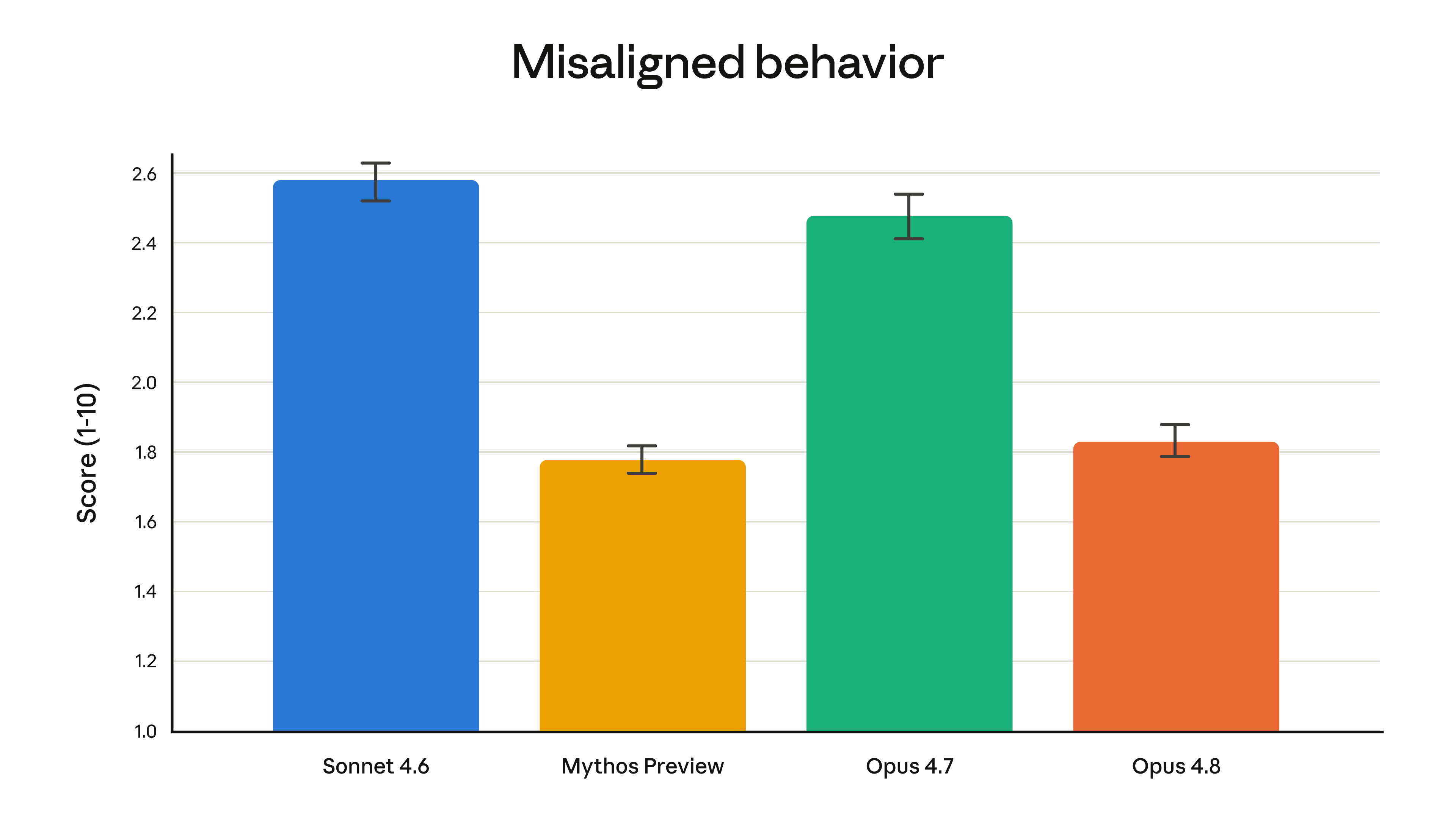
現在把上一章那一格輸掉的數字接回來。一家公司在自己的發表圖裡留一格敗績、還主動補上更難看的版本——這跟它主打「誠實」的模型,是同一個動作。產品在替發表稿示範它想賣的東西。這比任何一句行銷標語都有說服力。
我自己會這樣理解這次升級的價值。想像你帶一個 junior:A 每次都說「沒問題交給我」,結果三次有一次悄悄出包;B 會在卡住的時候舉手說「這段我不確定,你要不要看一下」。長期下來,你敢把重要的東西交給 B,不敢交給 A。Opus 4.8 想做的,是從 A 變成 B。
「我寧可要一個會說『這裡我不確定』的協作者,也不要一個每次都拍胸脯、最後讓我自己抓蟲的天才。」
RIVEN · 2026
這也接上了 4.7 的故事。我之前寫過,Opus 4.7 的招牌是「嚴格照字面執行」——你叫它做什麼它就做什麼,不再自行詮釋。那一代解決的是「聽不聽話」。4.8 往前走一步,補的是「有沒有判斷力」:它會問對問題、會在計畫不合理時踩煞車、會抓自己的錯。聽話加上判斷,協作者的樣子才算完整。
CHAPTER 04 · IN PRACTICE
設計師與內容創作者怎麼用
跑分跟你日常無關,能不能省你時間才有關。我把這次的更新翻成三個實際場景。


一、學會把「努力程度」往下調
多數人看到 effort control 的直覺是「永遠開最高」。這是用錯了。這個開關真正的價值在往下調,不在往上。
預設值(High)
官方判斷品質與體驗最平衡的檔位。日常九成的事用這檔就好,不用動它。
往上開(Extra / Max)
難題、需要長時間自己跑的非同步任務才開。它會燒更多 token 換更好的結果。官方建議困難任務用「extra」。
往下調(被低估的用法)
改錯字、調語氣、查一個小資料這種輕活,調低檔回得更快,而且更省你的用量額度。把額度留給真正難的事,這才是這個開關的精髓。
二、敢把長任務丟著不管
Opus 4.8 能更久地獨立工作,配上 Claude Code 的 dynamic workflows,可以一次處理過去得分好幾段才能跑完的大任務。對需要寫程式、做整站改版、跑大批內容的人,這代表你可以把任務交出去、去做別的事,回來再驗收。官方這支影片示範的就是這個——讓 Opus 4.8 接手長時間任務:
▲ 官方示範:用 Opus 4.8 與 Claude Code 處理長時間任務|來源:Claude 官方頻道
三、把它當會挑毛病的審稿人
既然它更會主動標記問題,就別只叫它「生產」,要叫它「挑錯」。把你寫好的文案、排好的版面邏輯、做好的分析丟給它,明講「找出你不確定或可能有問題的地方」。4.8 在這種任務上的回饋,會比前幾代更敢踩你痛點,而不是一味稱讚。對一個人撐多個產品線的創作者來說,這等於多了一個不用排班的審稿同事。如果你還沒把 Claude 接進日常設計工作,我之前整理過一套設計師的 AI 工作系統,可以當起手式。
CHAPTER 05 · LIMITS
限制與該有的期待
講完優點,照慣例潑點冷水。Opus 4.8 是「明顯但溫和」的進步,這是 Anthropic 自己的用詞,我認同。它不是那種讓你「哇」一聲的世代躍進。
跑分多半是個位數百分點的提升,電腦操作那項甚至只多 0.6%。終端機程式還輸給 GPT-5.5。如果你是 4.7 的重度用戶,日常單次體驗的差別可能不會太戲劇化——真正的價值要在「長期靠它交差」的累積裡才看得出來。
另外,Anthropic 提過會有比 Opus 更聰明的新一代模型,目前叫 Mythos,但還沒對一般用戶開放,要等更強的資安防護到位,官方說「未來幾週」。dynamic workflows 也還是研究預覽,而且只給 Enterprise、Team、Max 方案。免費跟低階方案用不到 Opus,這點沒變。
所以該有的期待是:把它當成 4.7 的可靠度升級版,不是革命。值得換,但別期待換完世界就不一樣。想看上一代到底升級了什麼,可以對照我寫的 Opus 4.6 完整介紹,這樣整條 4.x 的演進線就接得起來。
CHAPTER 06 · TAKEAWAYS
重點整理
這次發表最值得帶走的一句話:模型的競賽正在從「誰更聰明」悄悄轉向「誰更可信」。對天天靠 AI 產出交差的人來說,一個會說「我不確定」的模型,價值遠超過跑分表上多出來的那兩格。


常見問題
Q:Claude Opus 4.8 什麼時候發布、要怎麼用?
A:2026 年 5 月 28 日發布,當天全面開放。可以在 claude.ai、Claude Code 跟 Claude API 使用,API 模型代號是 claude-opus-4-8。需要付費方案才用得到 Opus。
Q:Opus 4.8 比 Opus 4.7 強多少?
A:跑分上多為個位數百分點的提升,例如寫程式的 SWE-Bench Pro 從 64.3% 到 69.2%。但最大的差異不在數字,而在可靠度與誠實——它更會主動標記自己不確定的地方,讓程式帶瑕疵卻不吭聲的機率比 4.7 低約四倍。
Q:價格有漲嗎?
A:沒有,跟 4.7 一樣。一般用量每百萬輸入 token 5 美元、輸出 25 美元;快速模式 10 美元 / 50 美元,速度 2.5 倍且比之前便宜三倍。
Q:effort control(努力程度)這個新開關該怎麼設?
A:日常用預設的高檔就好。難題或長時間任務往上開 extra / max 換更好結果;改錯字、查小資料這種輕活往下調,回得快又省額度。重點是學會往下調,別永遠開最高。
Q:設計師有需要從 4.7 換到 4.8 嗎?
A:值得換,而且無痛。同價格、可靠度更好、更會挑出你產出裡的問題。但別期待革命性差異——把它當 4.7 的可靠度升級版看待最準確。
Q:Opus 4.8 是 Anthropic 最強的模型嗎?
A:是目前一般用戶能用到的最強。Anthropic 另有一個更聰明的 Mythos 系列,但還沒普遍開放,要等更強的資安防護到位,官方說未來幾週。

