Claude Opus 4.7 發表:目前公開可用的最強 Opus,視覺能力大三倍、指令遵循更嚴謹

2026年4月16日 下午 4:15
AI 設計CHAPTER ONE
當 AI 開始懂得
「先驗證再回答」
Claude Opus 4.7 發表:我們現在用的,是目前最強的 Opus

Claude Opus 4.7 官方主視覺|圖片來源:Anthropic
2026 年 4 月 16 日,Anthropic 發表了 Claude Opus 4.7 — 距離 Opus 4.6 上市僅僅兩個月。這個版號聽起來像是小升級,但看完官方技術文件後,我覺得這是一次「安靜但重要」的進化。
如果你是設計師、內容創作者、或每天都在跟 AI 協作的人,這次更新有幾個變化值得知道:它能看懂更大的圖、更照字面執行你的指令、而且會先自己驗證輸出再交稿給你。
而且定價跟 Opus 4.6 完全一樣。
目錄 / CONTENTS
01Opus 4.7 是什麼?三個最值得關注的升級
02視覺處理從 768 px 拉到 2,576 px
03指令遵循更「認真」:為什麼舊 prompt 要重寫
04新的 xhigh 思考檔位、Claude Code 的 ultrareview
05設計師與創作者可以怎麼用
06從 Opus 4.6 升級到 4.7 要注意的事
CHAPTER TWO
Opus 4.7 是什麼?
三個最值得關注的升級
先講最核心的結論:Opus 4.7 是 Anthropic 目前公開可用的最強模型。它跟官方內部那個「更強但不公開」的 Claude Mythos Preview 不一樣 — Mythos 因為網路安全疑慮被鎖在 Project Glasswing 計畫裡、限量釋出,而 Opus 4.7 是大家現在就能用的版本。
對大多數人來說,這次更新可以濃縮成三件事:
升級一
視覺能力拉到 3.75 百萬畫素
圖片可以丟 2,576 px 長邊,比前代大三倍多。UI 設計稿、密集儀表板、技術圖表終於能看清楚細節。
升級二
指令遵循變得非常認真
它現在會照字面執行你的要求,不再隨意跳過、或自行詮釋。官方甚至建議重寫舊 prompt。
升級三
會自己驗證輸出再交稿
長任務中會主動檢查邏輯、找出自己的錯誤,而不是假裝搞定。這點 Vercel 的工程師甚至說看到它「先寫證明再開始動手」。
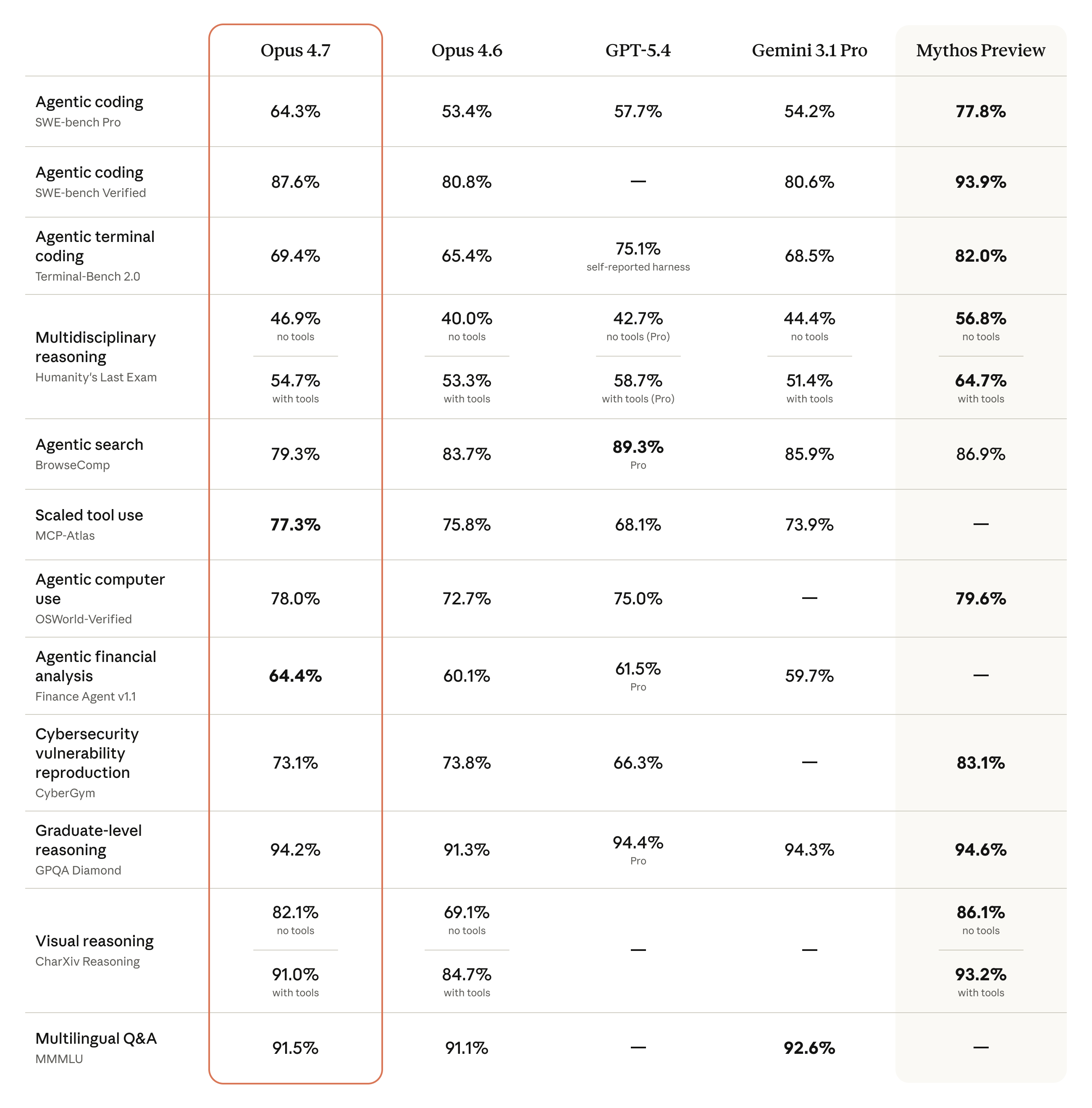
Opus 4.7 vs 4.6 / GPT-5.4 / Gemini 3.1 Pro / Mythos Preview 完整 benchmark 對照|圖片來源:Anthropic
"你可以把最困難的工作放心交給它,
不用全程盯著。"
— ANTHROPIC 官方
CHAPTER THREE
視覺處理:從「大概看懂」
變成「看得懂細節」
這一項是我最興奮的。
過去的 Claude 模型接受的圖片長邊上限大約 768 px,對於截圖 Figma 完整畫布、丟一頁 UI kit 給它分析、或是密集的資料儀表板來說,實務上常常是「看得出大概輪廓、細節全糊掉」。Opus 4.7 把這個上限拉到 2,576 px(約 3.75 百萬畫素),等於原本的三倍以上。
官方給的例子是「生命科學的專利技術圖」、「化學結構圖」、「複雜的技術示意圖」。但對設計師來說,這個變化更日常:
◆截一張完整的 Figma 工作區,讓它幫你評估資訊架構
◆丟一張密密麻麻的海報稿,請它挑出字級階層問題
◆把競品的完整落地頁截圖丟進去,請它分析動線
◆上傳手繪草稿,讓它協助轉成完整 wireframe 說明
過去這些情境常常要把圖切成好幾張、或先用其他工具把關鍵區域放大,現在可以一張到位。
官方文件裡特別提到一個有意思的細節:XBOW 的資安工具測試中,Opus 4.7 在他們的「視覺敏銳度」基準測試從 Opus 4.6 的 54.5% 直接跳到 98.5%。這不是 10%、15% 的改善,是從「常常看錯」變成「幾乎都對」的那種跳躍。
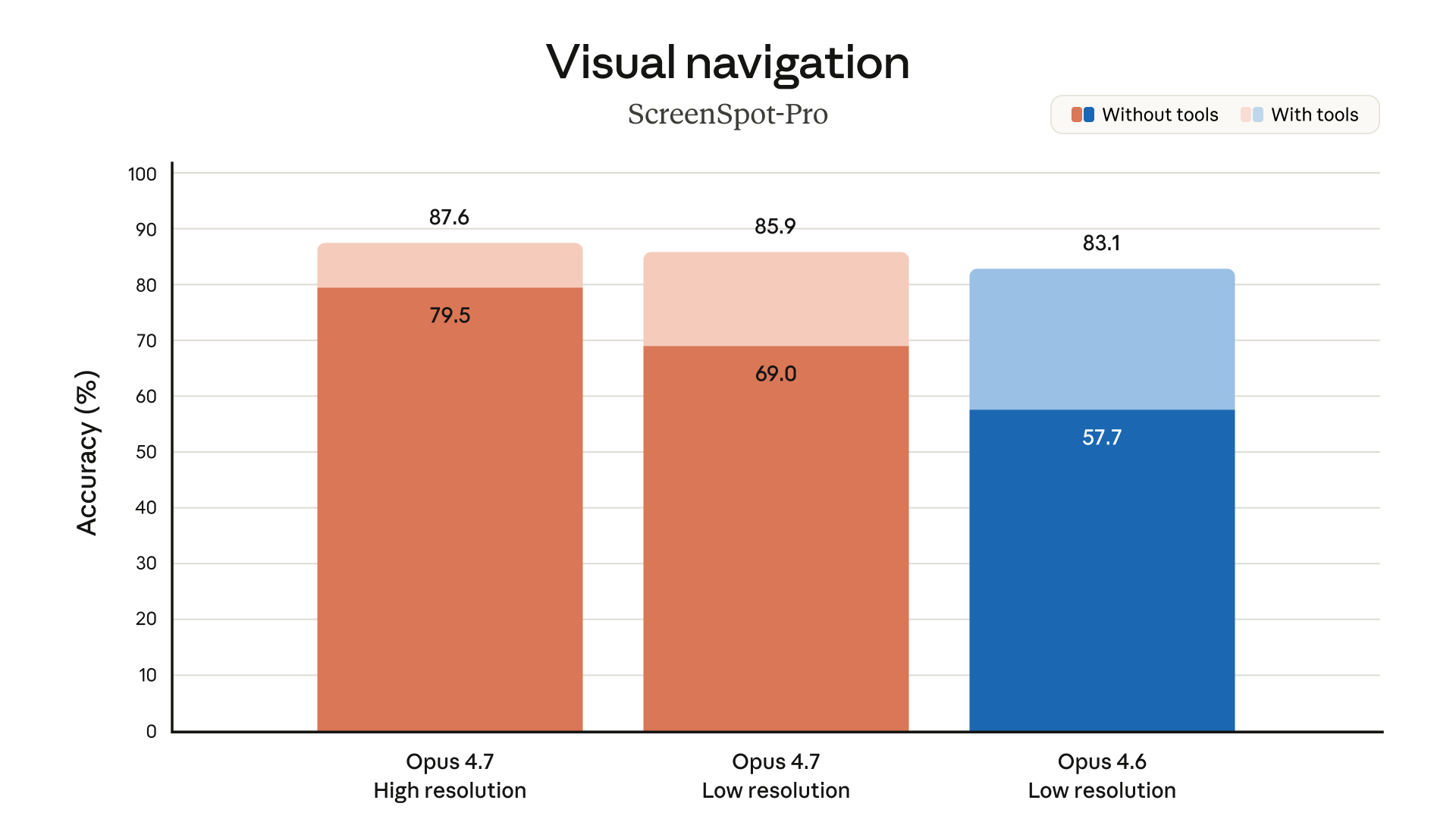
Opus 4.7 視覺能力評測|圖片來源:Anthropic
CHAPTER FOUR
指令遵循:為什麼
你的舊 prompt 可能需要重寫
這一段值得特別說,因為它有點反直覺。
以往 Claude 模型在面對冗長、模糊、或相互矛盾的指令時,會「自行詮釋」— 它會挑重要的執行、忽略不合理的、或者把你的要求轉譯成它覺得更好的版本。很多時候這樣反而省事。
Opus 4.7 不這樣了。它會非常認真地按照字面執行你的每一個要求。
官方在公告裡直接寫:「為早期模型寫的 prompt 有時可能會產生意料外的結果 — 過去模型會鬆散詮釋或跳過的指令,Opus 4.7 會照字面執行。使用者應該重新調整他們的 prompt 跟 harness。」
這個改變對於建立「可靠、可重複」的 AI 工作流來說是大利多 — 你不用再擔心模型今天突然發揮創意;但同時也代表你過去那些寫得有點模糊的 prompt,現在要回頭整理。
舉個實際例子:如果你過去寫「幫我寫一篇輕鬆的 IG 貼文,大概 300 字,別用 hashtag」,Opus 4.6 可能會給你 280-350 字隨便發揮。Opus 4.7 會更嚴格地把字數控制在 300 字附近、且真的一個 hashtag 都不放。這不是壞事,但代表你要把真正想要的邊界寫清楚,不要留模糊地帶。
CHAPTER FIVE
其他值得注意的更新
新的 xhigh 思考檔位
Opus 4.7 在 high 跟 max 之間多了一個 xhigh 檔位。過去這兩個檔差距有點大 — high 夠用但偶爾想要更細緻,max 又貴又慢。xhigh 剛好卡中間,給你多一個在「推理深度」跟「回應速度」之間的平衡選項。Claude Code 已經把所有方案的預設檔位拉到 xhigh。
Claude Code 新指令:/ultrareview
這是我覺得很實用的一個新功能。輸入 /ultrareview 會啟動一個專門的「細心審稿」模式 — 它會像資深工程師做 code review 一樣,逐行讀你的變動、找出 bug 跟設計問題。Pro 跟 Max 方案使用者有三次免費體驗。
雖然它主打寫程式,但這個「刻意的深度審查」模式其實也適合設計師 — 當你用 Claude 生成長文章、課程大綱、提案書時,把 ultrareview 當成最後一道品管也很合適。
Task Budgets 任務預算(API 公測)
給開發者的新功能:可以預先設定 Claude 在一個任務中的 token 花費上限,讓它在長任務中自己分配資源、決定哪些環節要深思、哪些可以快速帶過。這對搭建 AI agent 的人來說是很有用的控制力。
Claude Code 新增 Auto Mode(Max 方案)
Max 方案使用者現在可以啟用 Auto Mode — Claude 會自己做決策、一路做完,你不用每一步都按確認。長任務跑起來順很多,但因為不是「跳過所有權限檢查」,風險比 YOLO mode 低一些。
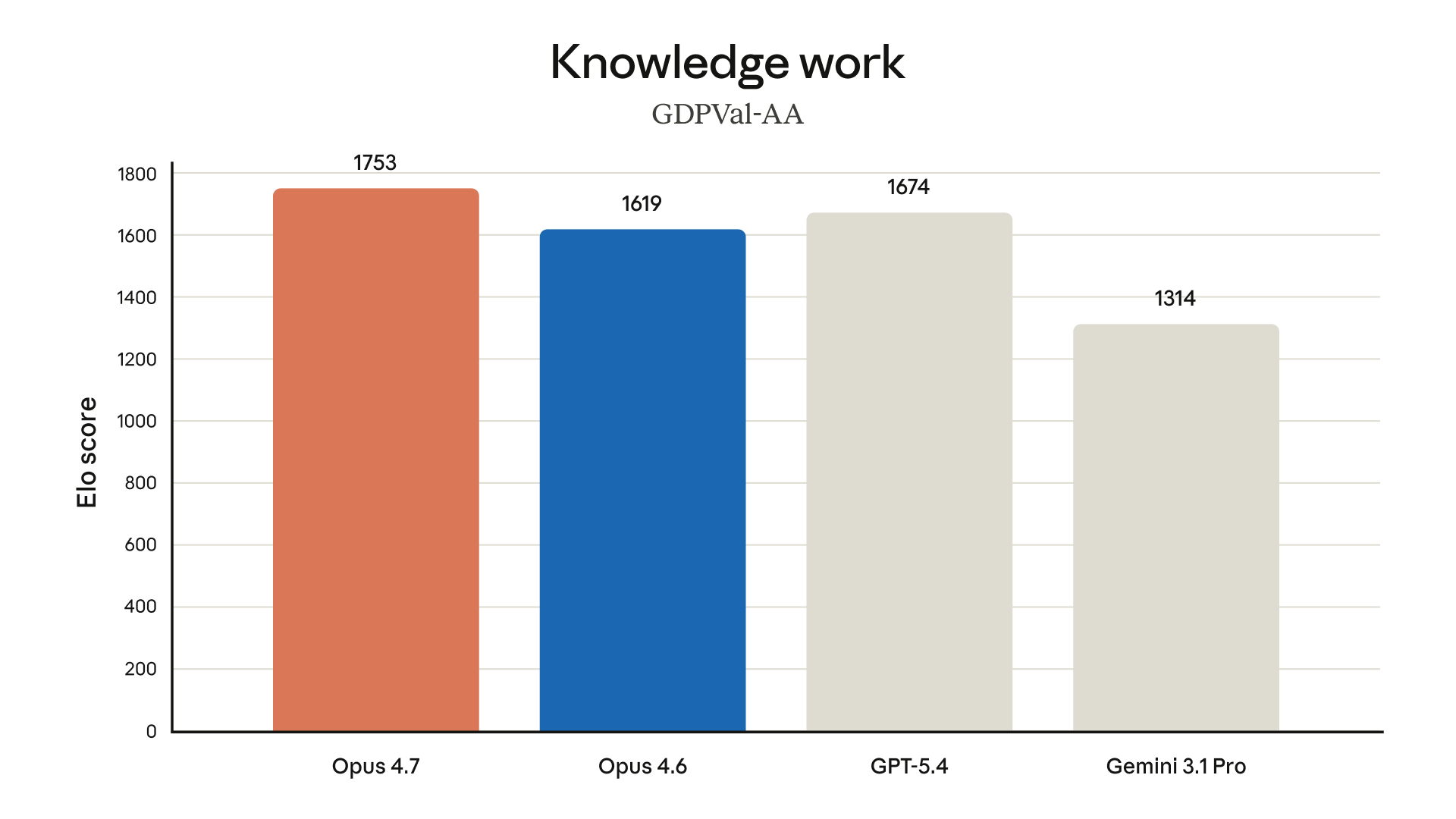
Opus 4.7 在 GDPval-AA 等真實知識工作評測中表現|圖片來源:Anthropic
CHAPTER SIX
設計師與內容創作者
可以怎麼用
把技術規格翻譯成實際應用場景,這是幾個我自己會立刻測試的方向:
場景 01 · 設計稿全圖審查
把 Figma 完整工作區或落地頁截圖丟進去,請 Opus 4.7 評估視覺層級、動線、CTA 擺位是否合理。2,576 px 的視覺能力讓它真的看得到按鈕上的字,而不是靠猜。
場景 02 · 嚴格規格的內容生成
過去跟 Claude 說「幫我寫 200 字 IG 貼文、不要表情符號、結尾用 ⬇️」常會有小偏差。Opus 4.7 的字面遵循能力讓這類「有嚴格規格」的文案任務穩定性大幅提升。
場景 03 · 長任務自動化
Anthropic 主打的是「把困難工作丟給它、不用盯」。對於經營訂閱制或日報的創作者,這代表像「每天抓五則設計新聞、整理摘要、排版、發文」這種多步驟流程,現在可以更放心讓 Claude 全自動跑。
場景 04 · 視覺參考素材分析
做風格研究時,把 Dribbble、Behance 上高解析度的作品參考丟進去,請它拆解配色邏輯、字型階層、留白策略。對準備課程教材或提案的人很實用。
這一代最大的改變,不是它變得更聰明,
而是它變得「更可靠」。
CHAPTER SEVEN
升級前要知道的事
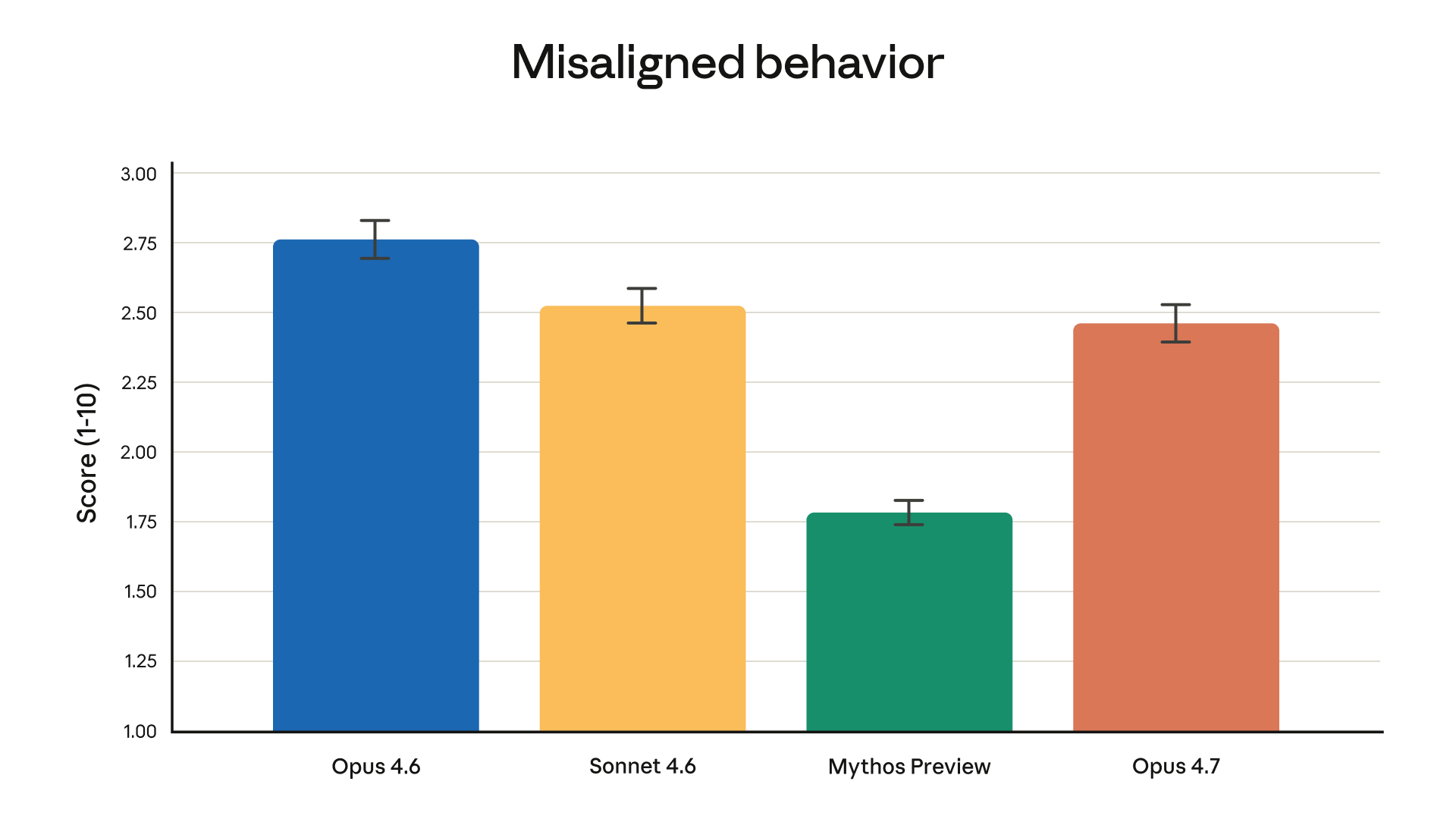
Opus 4.7 在自動化行為審核中的偏差行為分數(越低越好)|圖片來源:Anthropic
Token 用量可能略增
Opus 4.7 用了新的 tokenizer,同樣的輸入可能會對應到 1.0 到 1.35 倍的 token 數量(依內容類型而定)。加上它在高思考檔位時會花更多心思,輸出 token 也會變多。
Anthropic 官方說在他們的程式評測中,「每 token 的價值」是變高的 — 也就是花的 token 多,但任務完成度更高,整體 CP 值更好。但他們也建議大家在實際業務流量上測量看看,不要完全照官方數據。
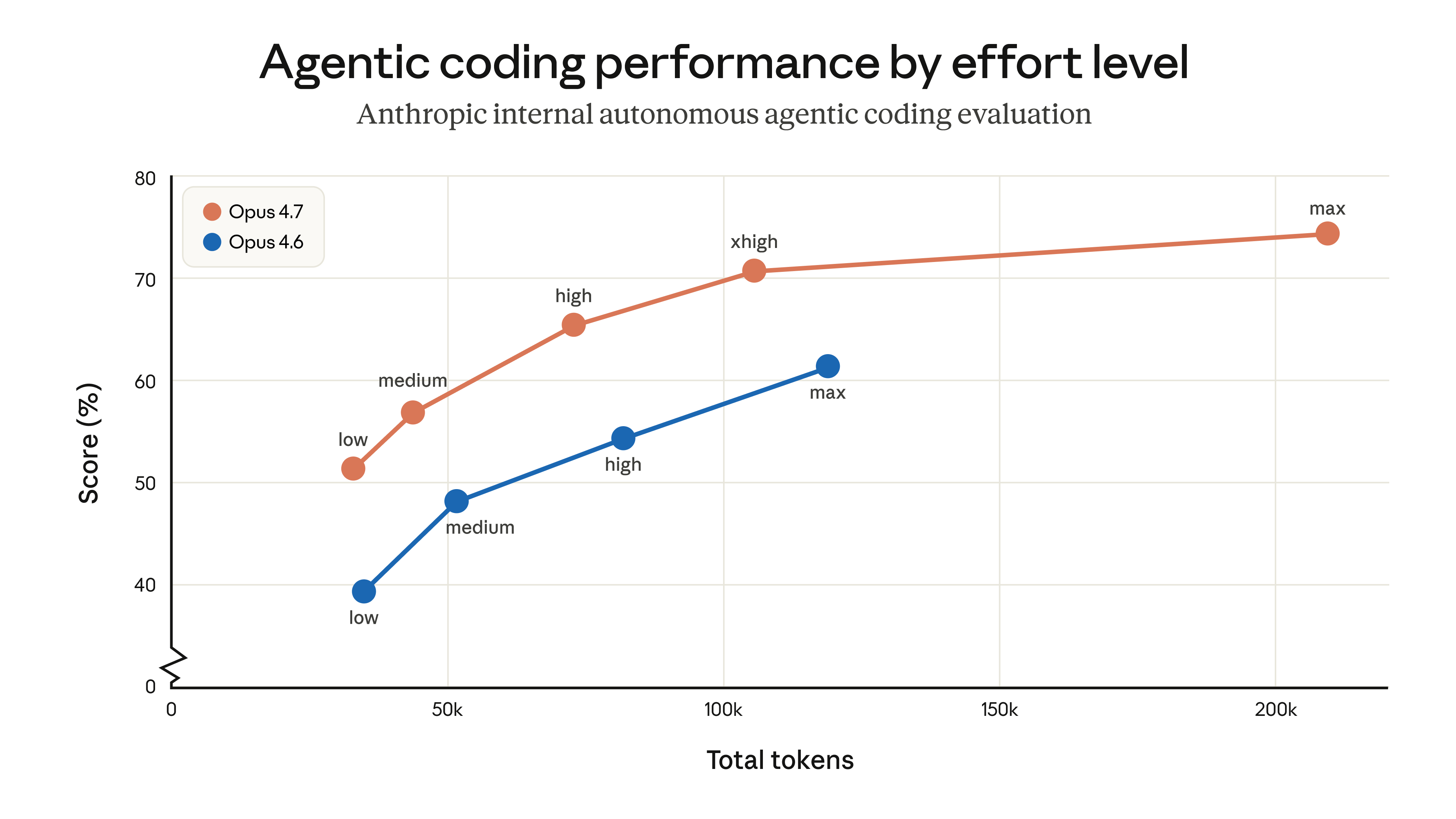
不同 effort 檔位的 Token 使用量 vs 得分關係|圖片來源:Anthropic
定價維持不變
API 定價跟 Opus 4.6 完全相同:每百萬輸入 token 5 美元、輸出 25 美元。Claude Pro、Max、Team、Enterprise 使用者都能直接切換到 Opus 4.7。
模型字串
API 用戶要切換模型,把 model 參數改成 claude-opus-4-7 就可以。Claude.ai 網頁跟 App 使用者在模型選單中直接選 Opus 4.7。
可用平台
Claude 產品、API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 全部同步上線。
重點整理
Opus 4.7 是 Anthropic 目前公開可用的最強模型,4/16 正式上線
視覺能力升到 2,576 px 長邊,密集設計稿、UI 截圖能看清楚細節
指令遵循變得很「字面」,舊 prompt 的模糊地帶建議重寫
長任務中會主動自我驗證,「先檢查再回報」成為預設行為
新增 xhigh 思考檔位,Claude Code 多了 /ultrareview 深度審稿指令
API 價格不變(輸入 $5 / 輸出 $25 每百萬 token),tokenizer 更新導致 token 用量略增
對設計師與內容創作者來說,這是一次「可靠性」的升級,而不只是「變更聰明」
AI 不會取代設計師,
但能讓你把省下的時間用在更重要的事上。
— RIVEN
延伸資源
